
FULLTEXT with N-GRAM 전문 검색을 사용해 보자
들어가며
웹사이트를 사용하다 보면 검색 기능을 쉽게 접할 수 있습니다. 기본적으로 많은 웹사이트는 엘라스틱서치(Elasticsearch)를 사용하여 손쉽게 검색 기능을 구현하고 개선합니다. 그러나 MySQL에서도 FULLTEXT와 N-GRAM을 지원하여 검색 기능을 최적화할 수 있습니다. 이번 포스팅에서는 MySQL을 사용하여 검색 기능을 최적화하는 방법에 대해 알아보겠습니다.
FullText Index

FULLTEXT 검색은 관계형 데이터베이스에서 텍스트 기반의 검색 기능을 제공하는 중요한 기술입니다. 특히 MySQL과 같은 데이터베이스에서는 FULLTEXT 인덱스를 통해 이 기능을 구현할 수 있습니다. 이 인덱스는 텍스트 필드 내의 단어들을 색인화하여 빠르게 검색할 수 있도록 돕습니다.
일반적으로 데이터베이스에서 LIKE 문을 사용하여 검색할 때는 데이터가 적을 때는 빠를 수 있지만, 데이터가 많아지면 성능 문제가 발생할 수 있습니다. 특히 LIKE 문에서 %_, _%, %_%과 같은 와일드카드 패턴을 사용할 경우 인덱스를 효과적으로 활용하기 어렵습니다. 이때 FULLTEXT 인덱스는 이러한 패턴 검색을 지원하며 빠른 속도로 데이터를 검색할 수 있습니다.
예를 들어, FULLTEXT 인덱스를 사용하여 다음과 같은 검색을 수행할 수 있습니다:
- LIKE 'apple%': FULLTEXT 인덱스는 이 패턴을 지원하여 빠르게 결과를 반환할 수 있습니다.
- LIKE '%orange%': FULLTEXT 인덱스 역시 이러한 패턴을 효율적으로 처리할 수 있습니다.
FULLTEXT 검색은 단순히 텍스트 매칭을 넘어서, 단어의 의미론적인 관계나 가까운 거리에 있는 단어들을 검색할 수 있는 기능도 제공합니다. 이는 사용자가 원하는 검색 결과를 더 정확하게 찾을 수 있도록 도와줍니다.
FULLTEXT 검색
FULLTEXT검색은 일반적으로 다음과 같은 필드 유형에만 적용됩니다.
CHAR
VARCHAR
TEXT
FULLTEXT 인덱스 생성
인덱스 생성 방법
CREATE FULLTEXT INDEX idx_name ON table_name(column1, column2, ...);
사용 방법
- IN NATURAL LANGUAGE MODE
SELECT * FROM TABLE
WHERE MATCH(column) AGAINST ('keyword' IN NATURAL LANUGUAGE MODE);- 키워드 토큰화: 검색할 키워드를 공백을 기준으로 토큰화하여 각각의 단어로 분리합니다. 예를 들어, "apple pie"라는 검색어는 "apple"과 "pie"로 분리됩니다.
- 단어 포함 검색: 분리된 각 단어 중 하나라도 테이블의 해당 컬럼에 포함되어 있으면 해당 레코드를 검색 결과로 반환
합니다. 즉, OR 조건과 비슷하게 동작하며, 하나 이상의 단어가 포함된 레코드를 검색합니다.
- IN BOLEAN MODE
SELECT * FROM TABLE
WHERE MATCH(column) AGAINST ('keyword' IN BOOLEAN MODE);
- 키워드 분리: 검색할 키워드를 공백을 기준으로 토큰화하여 각각의 단어로 분리합니다. 예를 들어, "apple pie"라는 검색어는 "apple"과 "pie"로 분리됩니다.
- 부울 연산자 사용: BOOLEAN MODE에서는 부울 연산자(+, -, *, " 등)를 사용하여 검색 조건을 명확히 할 수 있습니다.
| Operate | Description |
| + | 반드시 포함하는 단어 |
| - | 반드시 제외하는 단어 |
| > | 포함하면서 검색 순위를 높일 단어 |
| < | 포함하지만 검색 순위를 낮출 단어 |
| () | 하위 표현식으로 그룹화 |
| ~ | '_' 연산자와 비슷하나 제외 시키지 않고 검색 조건 낮춤 |
| * | 와일드 카드 |
| "" | 구문 정의 |
FULLTEXT 인덱스 설정
show variables like '%ft_min%';
단어를 2글자로 검색하게 된다면 검색이 되지 않습니다. 왜냐면 기본적으로 검색되는 단어의 길이가 4로 되어있는걸을 볼 수 있습니다. 만약 2 글자도 검색이 가능하게 하고 싶으면 설정을 변경하시면 됩니다.(my.ini, cnf의 파일에서 ft_min_word_len="바꿀 길이수" 변경하시면 됩니다.)
일반 검색
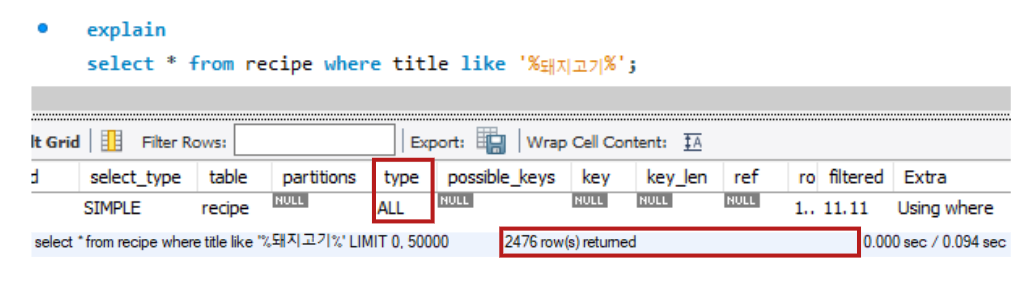
FullText 검색

일반 like문을 사용 시에 테이블 풀스캔을 통해 모든 데이터를 조회했지만, 인덱스를 생성 후 match() - against()을 사용하게 되면 fulltext인덱스를 사용하면서 성능적인 우의를 찾는 것을 볼 수 있습니다.
하지만 조회되는 데이터의 수가 다른 것을 볼 수 있습니다. 문제의 원인은 FULLTEXT 인덱스에서 사용되는 토큰화 방식에 있습니다. FULLTEXT 검색에서는 기본적으로 공백을 기준으로 단어를 분리하여 토큰화합니다. 따라서 "돼지고기"와 "돼지고기"는 다르게 인식될 수 있습니다.
N-GRAM

N-GRAM은 텍스트를 N개의 연속된 문자 또는 단어로 분할하는 방법입니다. 이를 통해 텍스트의 부분 문자열을 검색할 수 있게 합니다. 예를 들어, "hello"라는 단어를 2-그램(바이그램)으로 분할하면 다음과 같은 조각들이 생성됩니다:
"he" , "el", "ll" , "lo"로 토큰을 만들게 됩니다. 띄어 씌기가 있을 경우, 띄어쓰기를 제거 후 하나의 단어로만 존재하게 됩니다.
위에서 FullText만 사용했을 때 발생한 문제점을 해결하려면 N-gram을 함께 사용한 인덱스를 생성하면 됩니다.
FULLTEXT With N-gram 인덱스 생성
ALTER TABLE example ADD FULLTEXT INDEX ngram_idx (content) WITH PARSER ngram;
생성 후 실행하 보면 FullText 인덱스를 사용하는 것을 볼 수있다. 하지만 13개가이난 무려 10705개가 조회된것을 볼수 있다.
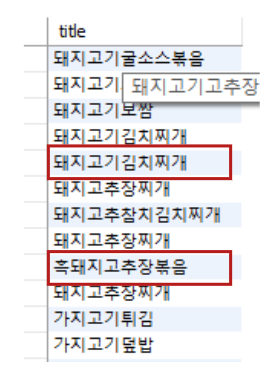
조회된 데이터를 보면 "돼지", "고기" 단어가 들어간 단어가 조회되면서 데이터가 많은 데이터를 조회되는 것을 볼 수 있다.
FULLTEXT With N-gram 인덱스 단점
- 너무 많은 데이터 조회: N-gram을 사용하면 특정 단어의 일부만으로도 해당 단어를 포함한 많은 데이터가 조회될 수 있습니다. 예를 들어, "돼지"와 "고기"라는 두 단어가 각각 포함된 모든 데이터가 조회될 수 있습니다. 이는 사용자가 원하는 검색 결과와 실제로 조회된 결과가 다를 수 있는 원인이 됩니다.
- 정확도 저하: 특히 단어의 일부만으로 조회되는 경우, 원하는 결과와 다른 데이터가 섞일 수 있어 검색 결과의 정확도가 저하될 수 있습니다.
- 성능 저하: N-gram을 사용하여 데이터베이스를 쿼리 할 때는 추가적인 연산이 필요하며, 많은 데이터가 조회될 경우 성능이 저하될 수 있습니다.
- 문맥 파악의 어려움: N-gram은 단어의 일부를 기반으로 검색을 수행하기 때문에 문맥을 완전히 이해하지 못할 수 있습니다. 예를 들어, "돼지고기"라는 단어가 포함된 데이터는 "돼지"와 "고기"라는 단어가 각각 포함된 데이터와 다를 수 있습니다.
정리
하지만 기본적인 MySQL에서 지원해 주는 것만으로도 많은 성능 개선되는 것을 볼 수 있습니다. 아래와 같이 같은 돼지고기를 검색하면

2476건의 데이터를 조회하는 데 0.093sec 걸린반면 10705건을 조회하는데 걸린 시간은 0.032 sec가 걸린 것을 보면
엄청 빠른 속도로 검색되는 것을 확인할 수 있습니다. 검색조건을 추가하거나 위에 작성한 부울 검색을 활용해서 잘만 적용한다면 MySQL에서도 충분히 빠른 속도로 검색이 가능할 것 같습니다.
Reference
MySQL :: InnoDB 전문 검색 : N-gram Parser
기본 InnoDB 전문 검색(Full Text) 파서는 공백이나 단어 분리자가 토큰인 라틴 기반 언어들에서는 이상적이지만 개별 단어에 대한 고정된 구분자가 없는 중국어, 일본어, 한국어(CJK)같은 언어들에서
dev.mysql.com
'MySQL' 카테고리의 다른 글
| [MySQL] CSV 파일 Import 및 Export: 간편 가이드 (3) | 2024.06.18 |
|---|---|
| [MySQL] 일정한 시간마다 쿼리를 실행하는 MySQL scheduled event 사용하기 (0) | 2024.03.29 |
| [MySQL] [2]인덱스(Index)란-"R-Tree, 전문검색(n-gram),함수 기반,멀티 밸류, 클러스터링,유니크"인덱스란? (0) | 2024.02.08 |
| [MySQL] [1]인덱스(Index)란-B-Tree? (0) | 2024.02.08 |
| [MySQL] 데이터 암호화란? (2) | 2024.01.27 |